
梁文锋押注的方向,中国00后团队先交卷了!性能直逼Opus 4.8
梁文锋押注的方向,中国00后团队先交卷了!性能直逼Opus 4.8上周AI圈都在讨论一件事,但大多数人只看到了一半。
来自主题: AI资讯
7150 点击 2026-07-27 10:48
 搜索
搜索
上周AI圈都在讨论一件事,但大多数人只看到了一半。

最近手头在测一个新模型,叫 Macaron-V1。说实话一开始没抱太大期待,打着「个人智能体」旗号的产品这两年太多了,大多数打开之后还是那套老配方:一个聊天机器人,外面挂几个插件。但测了三四天下来,发现这个模型的思路跟我预想的不太一样,值得认真写一篇。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。
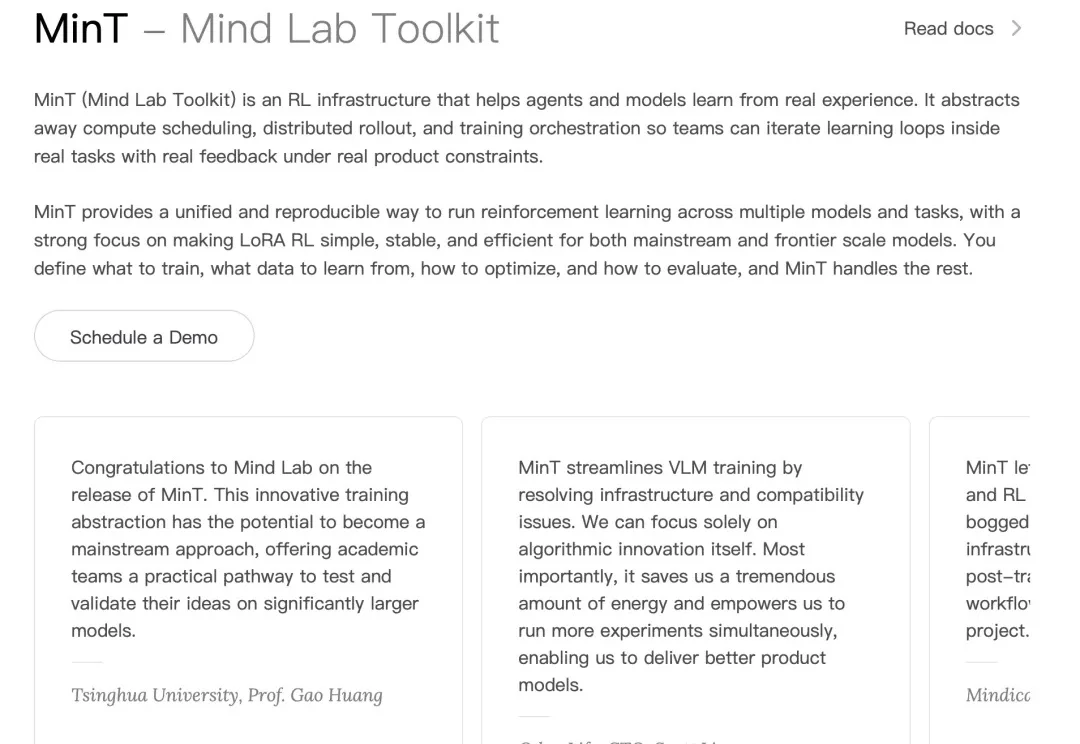
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。

最近刷到了 Macaron 发布的一条技术视频。